With Databricks Jobs being possible to be called from Azure Data Factory (not available in Azure Synapse Analytics as time of writing: November 2025), and being already Generally Available, one concern which might arise is working with JobIDs parameterization when promoting code to higher environments.
Purely, as an observation, when using this activity, the Job dropdown will list all the Jobs visible to the identity performing this listing operation:
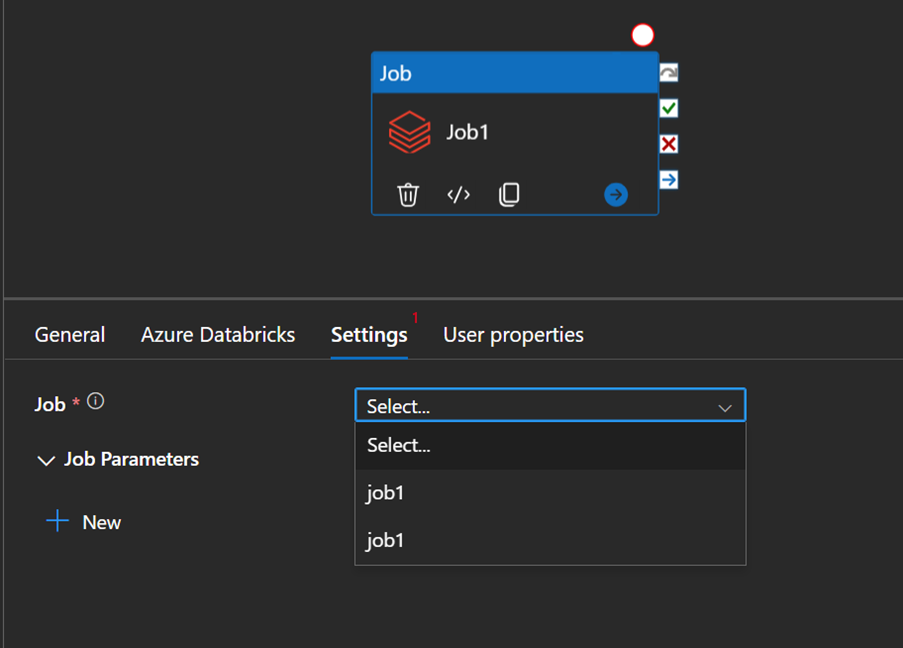
Of course, this is a corner case scenario which can be avoided with some governance, so Databricks jobs can be identified by name, but there are some nuances:
Job Name: When you create a job in Databricks, you assign it a name. This name is visible in the Jobs UI and through the REST API.
Uniqueness: Job names are not required to be unique. You can have multiple jobs with the same name, so the name alone is not a guaranteed unique identifier.
Best Practice: Use the Job ID for automation and integrations, This is the reliable way to identify a specific job programmatically or in automation scripts.
Having said that, I will now try to demonstrate how we can parameterize this field and work with parameters at deployment time.
Let’s start with this activity:
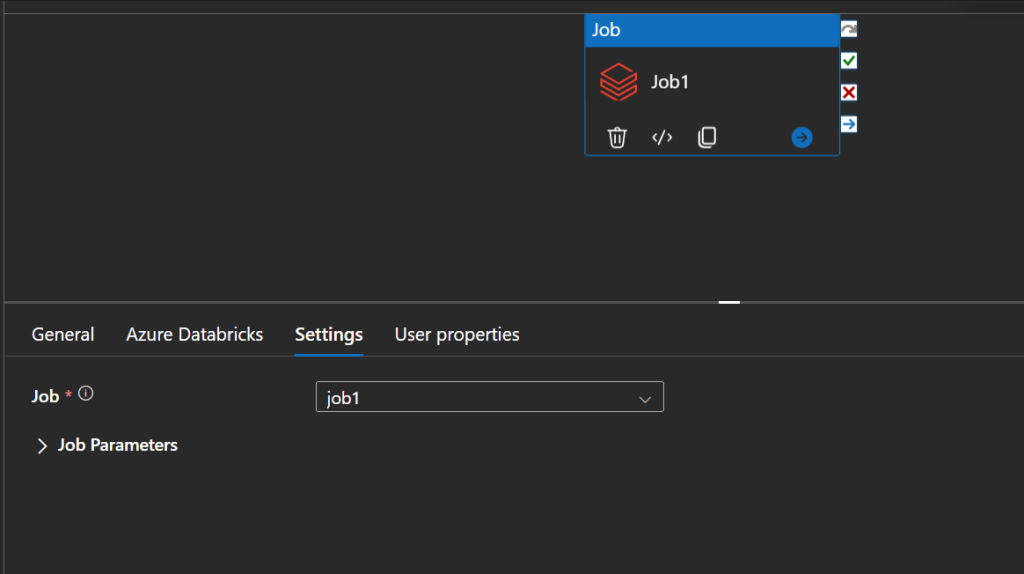
This is the corresponding payload, see how it refers to JobID, and no name is used:
{
"name": "pipeline2",
"properties": {
"activities": [
{
"name": "Job1",
"type": "DatabricksJob",
"dependsOn": [],
"policy": {
"timeout": "0.12:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"jobId": "743603170644169"
},
"linkedServiceName": {
"referenceName": "AzureDatabricks1",
"type": "LinkedServiceReference"
}
}
],
"annotations": []
}
}
This is how it looks like, in the ARM template:
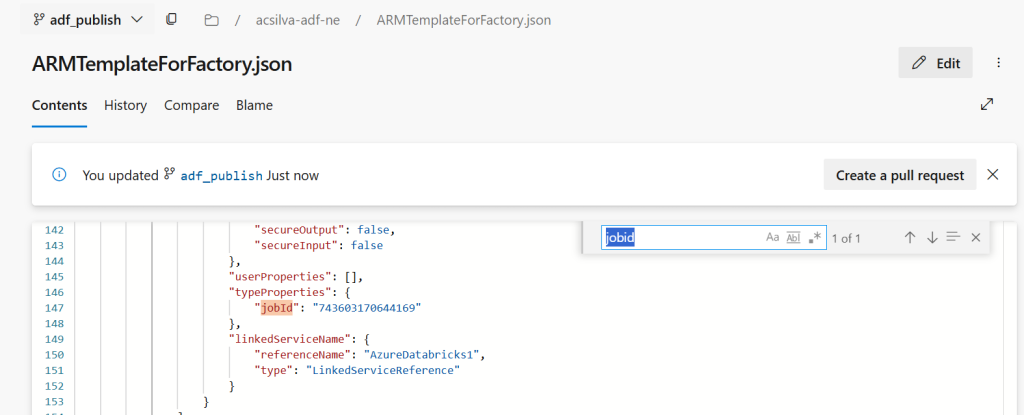
So, it’s not parameterized.
This means that, if you don’t change this, when promoting this to a higher environment, pointing to another Databricks instance, you won’t be pointing to the desired job, as the JobID is an unique identifier.
How to proceed, then? Leverage custom parameterization: https://learn.microsoft.com/en-us/azure/data-factory/continuous-integration-delivery-resource-manager-custom-parameters
Go to Manage > ARM template > Edit parameter configuration
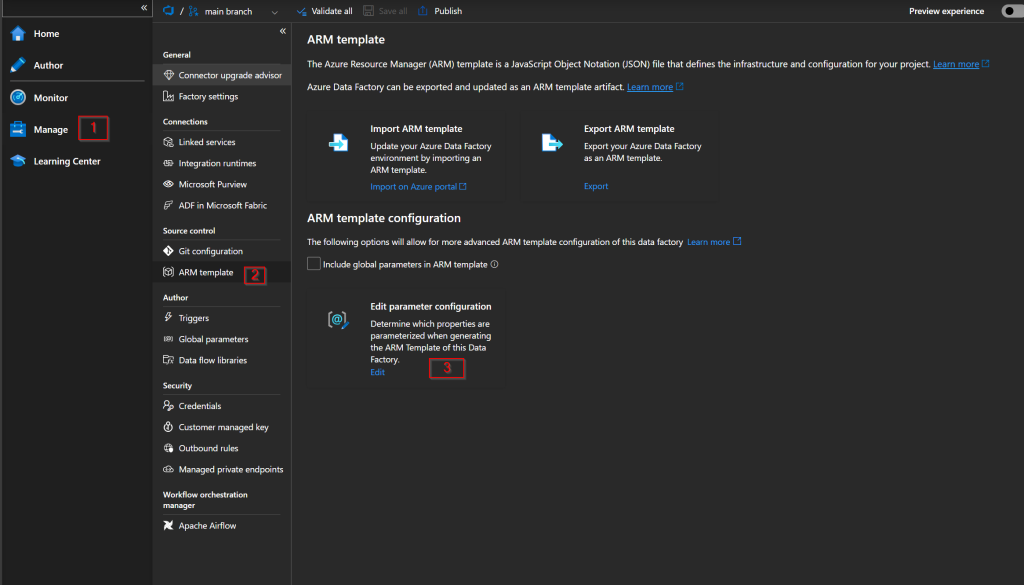
And this is the property we are interested in parameterizing: $.properties.activities.typeProperties.jobId
Therefore we need to edit the following payload for Microsoft.DataFactory/factories/pipelines:
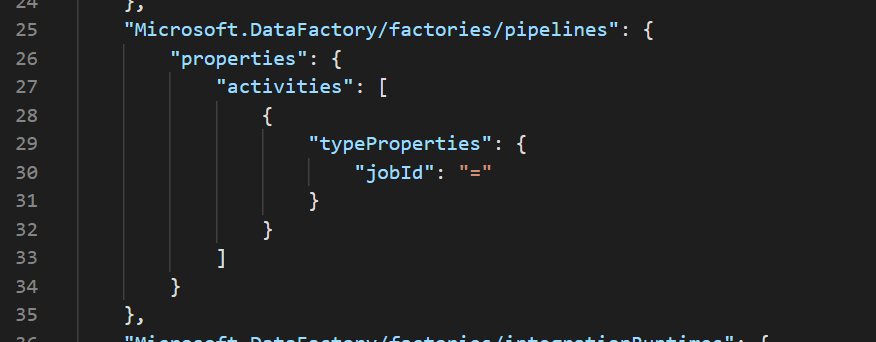
“Setting the value of a property as a string indicates that you want to parameterize the property. Use the format <action>:<name>:<stype>.”
Once this is applied, make a dummy change on a pipeline, just to make sure a new ARM template is generated.
As we chose to keep the default, this is how the ARM template looks like kow:

Regarding deployment, I will illustrate using an Azure DevOps task (CI/CD with Azure Pipelines and templates – Azure Resource Manager | Microsoft Learn).
We can now see how to parameterize this property, which can be overridden at deployment time:

This way, we can make sure “our” hardcoded Jobs will point to the right instance, when promoting code to higher environments.
As a warning of navigation, as you add more parameters, if you rely heavily on this pattern, you risk running into the following ARM limitation: 256 parameters (https://learn.microsoft.com/en-us/azure/azure-resource-manager/templates/best-practices#template-limits)
If that’s your case, you may want to use a pipeline which takes a JobID as a parameter, which can be reused in a parent pipeline, as follows:
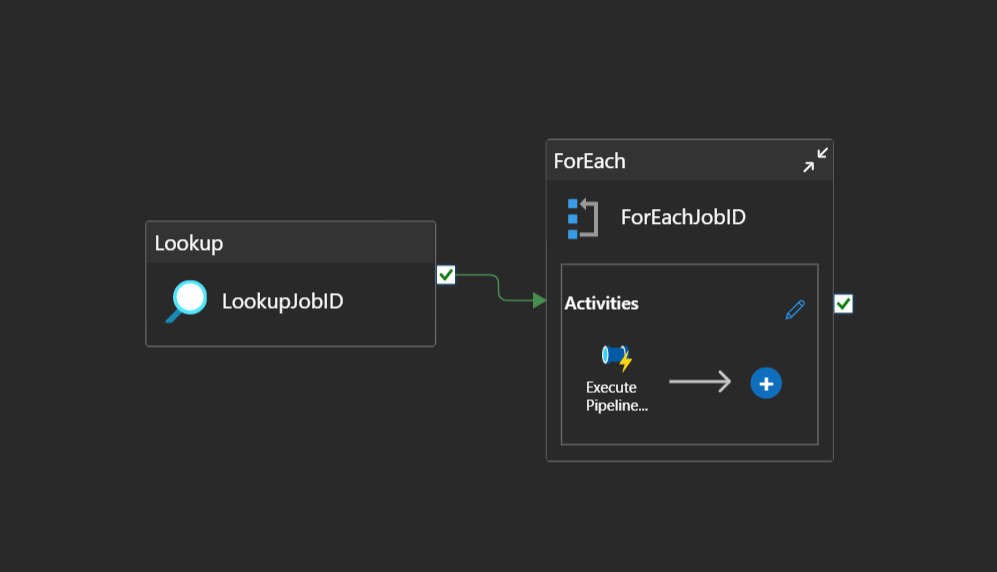
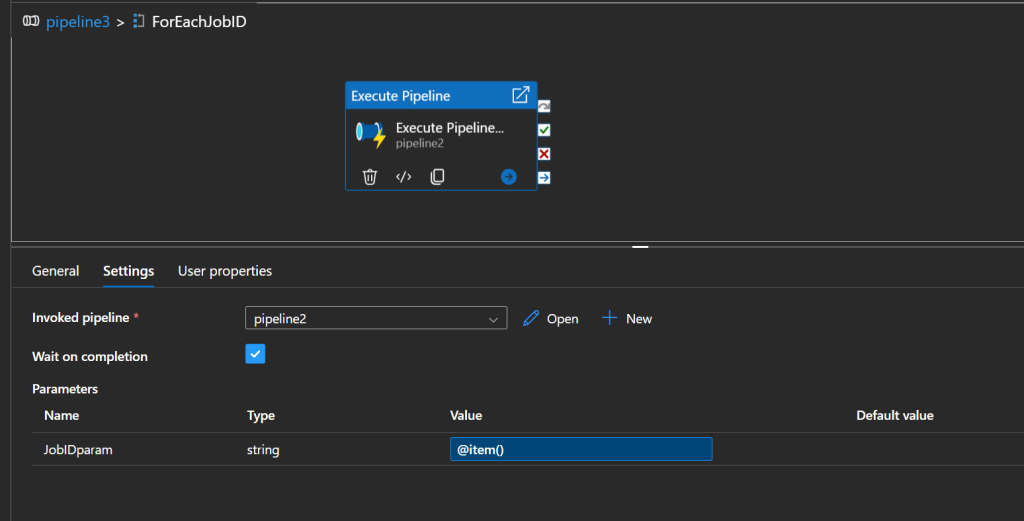
In here, you’d need to rely on a configuration table, or a mapping layer between names and ids.
I hope you found this useful, thanks for reading!